Dans le post précédent nous avons présenté de petites simulations numériques de la transmission d’un virus dans un lotissement. Nous avons vu que si les gens sont très mobiles, la phase de croissance de l’épidémie est exponentielle avec le temps. D’autre part le fait que les gens se « mélangent » produit une population homogène, où en chaque endroit on a à peu près les mêmes proportions de personnes saines, contaminées, guéries etc … Or on peut utiliser cette homogénéité de la population pour construire des modèles mathématiques assez simples.
Le modèle SI
Soit une population qui à un instant donné contient S personnes saines Susceptibles d’être infectées, et I personnes Infectées contagieuses. Peut-on décrire simplement la vitesse à laquelle les effectifs de ces deux groupes vont évoluer ? Pour cela nous allons supposer que tout se passe comme si les rencontres entre personnes étaient aléatoires. Plus la proportion de personnes infectées est élevée, plus la probabilité qu’une rencontre se fasse avec une telle personne est élevée. Ainsi on peut supposer que la probabilité qu’une personne rencontrée par une Susceptible soit Infectée, est proportionnelle au nombre I de personnes infectées. De plus le nombre total de telles rencontres se produisant dans un laps de temps donné est proportionnel au nombre total de personnes susceptibles S : il est donc proportionnel au produit IS. Le nombre de nouvelles contaminations qui se produisent pendant le laps de temps peut donc s’écrire 


Le coefficient
Voilà, nous avons déjà un modèle mathématique de propagation d’une épidémie !
Appelons-le le modèle SI. Pour l’implémenter il suffit de choisir des valeurs initiales I(1) et S(1) et une valeur de


Comme dans ce modèle minimaliste tous les infectés restent contagieux (ne guérissent ni ne décèdent) tout le monde fini par être atteint. Le tracé en échelles semi-logarithmiques à droite montre que jusque vers la 40ième étape la croissance du nombre d’infectés est exponentielle (une exponentielle donne une droite en échelles semi-log). C’est une conséquence des hypothèses du modèle. En effet les fonctions exponentielles sont celles dont l’accroissement d’une étape n à l’étape n+1 est proportionnel à leur valeur à l’étape n (si chaque étape correspond à un laps de temps très court pendant lequel les nombres varient peu). Or c’est ce que traduit la relation 

Le modèle SIR
Nous allons maintenant voir qu’il est assez simple de compléter le modèle. Par exemple nous allons introduire le fait qu’après un certain temps, les personnes infectées contagieuses guérissent et sont immunisées : on les dénomme alors par la lettre R (pour « Recovered » en anglais). On fait l’hypothèse (encore une !) qu’à chaque étape le nombre de personnes Infectées qui guérissent est proportionnel à leur effectif I, c’est à dire que les guérisons diminuent I d’une quantité de la forme 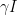
devient :

D’autre part l’effectif R du nouveau groupe des malades guéris croit selon 
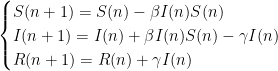
Comme précédemment on se donne un jeu de valeurs initiales S(1), I(1) et R(1), ainsi que des valeurs pour 

L’état contagieux est maintenant un état transitoire, dont l’effectif décrit un pic. Dans notre exemple l’état final est majoritairement constitué de personnes guéries, l’effectif qui n’a pas été touché (1000 personnes) est d’autant plus élevé que le paramètre
Taux de reproduction, immunité collective et vaccination
Quelle est la signification précise des paramètres 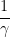


Une épidémie peut-elle être empêchée si seulement une partie de la population est immunisée par une épidémie antérieure ou une vaccination ? La réponse est oui, il faut pour cela que la fraction de la population protégée excède 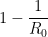
Justification : supposons qu’au départ seule une partie de la population soit susceptible, le reste étant immunisé. Introduisons quelques personnes infectées. Pour qu’une nouvelle épidémie se développe il faut que le nombre I se mette à augmenter, autrement dit il faut :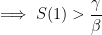
Inversement si 
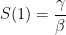
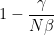


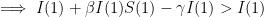

Concrètement quand l’épidémie se développe les nouvelles contaminations excèdent les guérisons. Au contraire dans le cas de l’immunité collective, le virus ne « trouve » pas assez de personnes saines à infecter pour compenser les guérisons.
Dans l’exemple de la figure plus haut le cas limite correspond à 

Pour la COVID-19 les valeurs estimées pour R0 sont de l’ordre de 3-3,5. Un taux d’immunisation de 66-70% est donc nécessaire pour empêcher un retour de l’épidémie sans mesure sanitaire spécifique.
Remarquons enfin qu’en l’absence d’immunité collective initiale, l’épidémie prend de l’ampleur jusqu’à ce que la condition 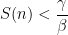
Modèle SEIRD … et plus si affinités
Vous le devinez on peut facilement ajouter de nouveaux groupes d’individus, il suffit pour cela de compléter le système de relations. Ainsi nous ajoutons le groupe E des personnes contaminées mais non encore contagieuses (personnes dans leur période d’incubation, Expected en anglais) et le groupe D des personnes décédées. Le modèle est alors défini par :

Vous pouvez vous amuser à identifier les différents termes. La première relation décrit le départ d’individus Susceptibles vers la catégorie Expected (en incubation), la seconde leur arrivée en Expected et le départ de certains vers la catégorie Infected (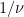


Nous donnons ci-dessous un exemple de courbes que l’on peut obtenir, avec un jeu de paramètres qui décrit une épidémie à fort taux de létalité puisque qu’à la fin de l’épisode plus de 60% de la population est décédée.

Un point « intéressant » est le suivant : on pourrai penser que si l’on augmente le risque de décès en augmentant la valeur du paramètre 
Bien entendu on peut encore compléter le modèle par exemple en introduisant une durée finie d’immunité (au bout d’un certain temps les individus R (immunisés) redeviennent Susceptibles), en distinguant différentes classes d’age qui ont chacune leurs paramètres propres, et si l’on fait une étude à plus long terme en prenant en compte les effets démographiques habituels (naissances et décès dus aux autres causes que la maladie). Cela permet de décrire plus finement ce qui se passe, mais multiplie les paramètres dont il faut fixer (parfois deviner) les valeurs.
Dans le prochain post nous regarderons comment décrire ce qui s’est passé en France avec le modèle SEIRD, en incluant le confinement et les effets possibles de différents scénarios de déconfinement.
Et nous nous livrerons à un petit examen critique de ce type de modèle : quelles en sont les limites ?
